Large-scale language models (LLMs) like Claude have changed the way technology is used. They help you write power tools like chatbots, essays, and even create poems. However, despite their incredible abilities, these models remain mysterious in many ways. People often can call them “black boxes.” This lack of understanding raises problems, especially in important areas such as medicine and law. There, mistakes and hidden prejudices can cause real harm.
Understanding how LLMS works is essential to building trust. It is difficult to trust the outcome, especially in sensitive areas, if the model cannot explain why it gave a specific answer. Interpretability also helps identify and correct biases and errors, ensuring that the model is safe and ethical. For example, if a model consistently likes a particular perspective, you can find out why it helps developers fix it. This need for clarity encourages research that makes these models more transparent.
Anthropic, the company behind Claude, is working to open this black box. They have made exciting advances in figuring out how LLMS thinks. In this article, we explore breakthroughs to make Claude’s process easier to understand.
Claude’s thoughts mapping
In mid-2024, the human team made an exciting breakthrough. They created a basic “map” of how Claude handles information. Using a technique called dictionary learning, they found millions of patterns in Claude’s “brain,” or neural networks. Each pattern or “feature” connects to a specific idea. For example, some features can help with Claude’s Spot City, Celebrities, or coding mistakes. Others are tied to tricky topics like gender bias and secrets.
Researchers found that these ideas were not isolated within individual neurons. Instead, they spread across many neurons in Claude’s network, each of which contributes to a variety of ideas. This overlap has made it anthropomorphic to understand these ideas in the first place. However, by finding these repetitive patterns, human researchers began to decipher the way Claude organizes his ideas.
Tracking Claude’s reasoning
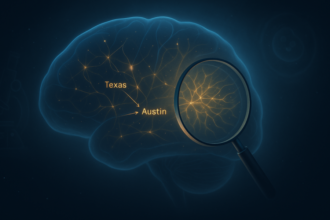
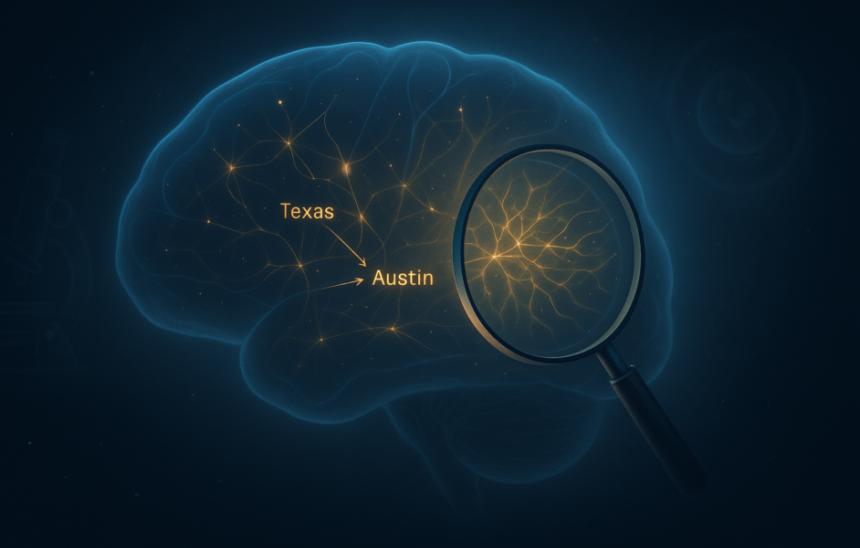
Secondly, humanity wanted to see how Claude used these ideas to make decisions. They recently created a tool called Attribution Graph, which acts like a step-by-step guide to Claude’s thought process. Each point in the graph is an idea that lights up in Claude’s mind, and the arrows show how one idea flows into the next. This graph allows researchers to track how Claude transforms questions into answers.
To better understand the behavior of attribution graphs, consider this example. “What is the state’s capital with Dallas?” Claude must realize that Dallas is in Texas. And remember that the capital of Texas is Austin. The attribute graph demonstrated this exact process. One part of Claude flagged “Texas” and another part chose “Austin.” The team tested it by tweaking the “Texas” part, but certainly changed the answer. This shows that Claude is not just speculating, but he is overcoming the problem, and now we can see it happen.
Why is this important: An analogy from biological sciences
To see why this is important, it is useful to think about some of the major developments in biological sciences. Just as the invention of microscopes allows scientists to discover cells (constituents of hidden life), these interpretability tools allow AI researchers to discover the constituents of thinking within models. And, just like mapping brain neural circuits and sequencing genomes, the path to a medical breakthrough can pave the way for more reliable and controllable mechanical intelligence by mapping Claude’s inner workings. These interpretability tools can play an important role and can help you peer into the thought process of AI models.
assignment
With all this progress, we are far from fully understanding LLM like Claude. Attribute graphs can currently only explain one in four Claude’s decisions. The map of its features is impressive, but it covers some of what’s going on in Claude’s brain. With billions of parameters, Claude and other LLMs perform countless calculations for every task. Tracking each one and seeing how the answers are formed is like trying to track the firing of every neuron in the human brain during a single idea.
There are also issues with “hagatsu” issues. AI models can sometimes produce responses that sound plausible, but are actually incorrect. This occurs because the model relies on patterns from training data rather than a true understanding of the world. Understanding why they are transformed into manufacturing is a difficult issue, highlighting the gap in their understanding of their inner workings.
Bias is another important obstacle. AI models learn from vast datasets that have been scraped off the Internet. From the Internet, it essentially carries human bias (zero type, bias, and other social flaws). If Claude takes these biases from training, it may reflect them in its answer. Unpacking where these biases occur and how they affect model inference is a complex challenge that requires both technical solutions and careful consideration of data and ethics.
Conclusion
Humanity’s work in making large-scale language models (LLMs) like Claude easier to understand is an important step in AI transparency. By clarifying how Claude processes information and makes decisions, it is forwarded to address key concerns about AI accountability. This advancement opens the door to safe integration of LLM into critical sectors such as healthcare and law where trust and ethics are essential.
As methods of improving interpretability develop, industries that are cautious about adoption of AI can now be rethinked. Transparent models like Claude offer a clear path to the future of AI. This is a machine that not only replicates human intelligence, but also explains reasoning.